Bagging

Bagging은 Bootstrap Aggregating의 약자이다.
배깅은 샘플을 여러 번 뽑아(Bootstrap) 각 모델을 학습시켜 결과물을 집계(Aggregration)하는 방법이다.
우선, 데이터로부터 부트스트랩을 한다. (부트스트랩: 복원 랜덤 샘플링)
부트스트랩한 데이터로 모델을 학습시킨다.
학습된 모델의 결과를 집계하여 최종 결과 값을 구한다.
Categorical Data는 투표 방식(Voting)으로 결과를 집계하며, Continuous Data는 평균값으로 집계한다.
랜덤 포레스트는 배깅 기법을 활용한 모델이다.
배깅에서 Decision Tree1과 Decision Tree2가 독립적인 결과를 예측한다.
(여러개의 독립적인 결정 트리가 각각 값을 예측한 뒤, 그 결과 값을 집계해 최종 결과 값을 예측)
Boosting
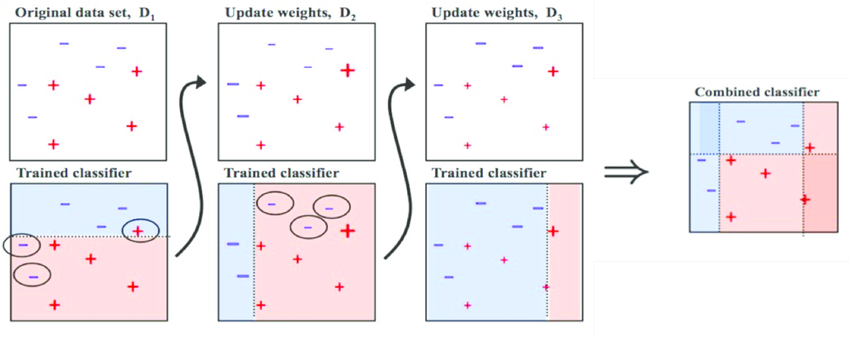
가중치를 활용하여 약 분류기를 강 분류기로 만드는 방법이다.
배깅과 달리 각 모델들이 독립적으로 결과를 예측하는 것이 아닌, 처음 모델이 예측을 하면,
그 예측 결과에 따라 데이터에 가중치가 부여되고, 부여된 가중치가 다음 모델에 영향을 준다.
잘못 분류된 데이터에 집중하여, 새로운 분류 규칙을 만드는 단계를 반복한다.
최종적으로 사용하였던 분류를 합쳐 최종 Classifier를 구한다.
차이점

부스팅은 배깅에 비해 error가 적다. 즉, 성능이 좋다.
하지만, 속도가 느리고 오버 피팅이 될 가능성이 있다.
개별 결정 트리의 낮은 성능이 문제라면 부스팅이 적합하고,
오버 피팅이 문제라면 배깅이 적합하다.